Le modèle relationnel est dominant
Lorsqu’on est amené à construire une application web on utilise en général le modèle relationnel (cette question ne se pose pas toutefois si on travaille avec une base de données de type NoSQL, comme MongoDB, Couchbase …). Nous utilisons tous finalement le modèle relationnel sans forcément en avoir conscience. Sa manière de fonctionner étant relativement naturelle. D’ailleurs si nous revenons une étape avant, on peut légitimement s’interroger sur ce qu’est un modèle de base de données… Il s’agit simplement de règles de construction et d’utilisation d’une base de données. Un modèle est en général très normé afin que l’architecture d’une base reste compréhensible même en cas de changement d’équipe.
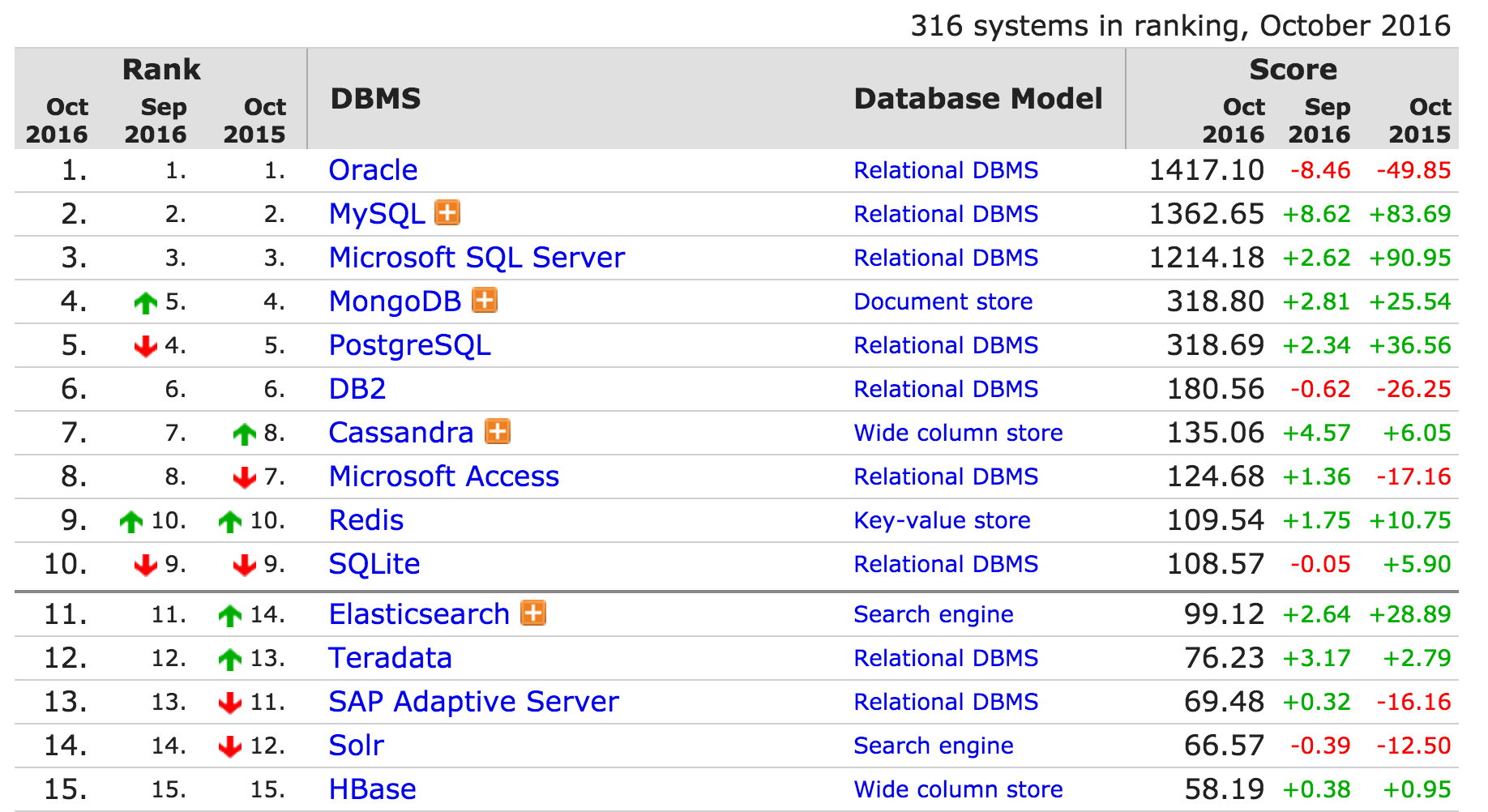
Les bases de données avec des modèles relationnels sont encore largement utilisées :
Caractéristiques du modèle relationnel
Modéliser une donnée de façon relationnel revient à penser les données de son application sous forme d’une multitude d’objets qui disposent de relations permettant de les lier ensemble. La modélisation de la base de données amène à la génération d’un schéma de la base de données. Cette définition semble abstraite, prenons un exemple pour mieux la comprendre : le commerce électronique.
Pour un site e-commerce nous avons plusieurs objets : des clients, des commandes, des adresses, des produits, des fabricants. Ces objets disposent d’une multitude de liens entre eux. Par exemple un client dispose de plusieurs adresses, une commande de produits, un client de commandes … On voit aussi que si certains objets ont des relations multiples avec d’autres, on a aussi des relations uniques entre certains objets. Un produit à par exemple un seul et unique fabricant. Il ne peut en avoir deux…
Les différents types de relations
Ainsi les liens entre les objets sont de différents types :
- 1-n : ou encore relations un à plusieurs par exemple entre l’objet client et l’objet commande : un client peut avoir plusieurs commandes, mais une commande ne peut avoir qu’un seul client.
- n-n : ou encore relations plusieurs à plusieurs : un produit peut avoir plusieurs couleurs et une couleur n’est pas spécifique à un produit. Il peut y avoir plus d’un produit de couleur X.
- 1-1 : ou encore les relations un à un par exemple si nous stockions les numéros de carte d’identité de nos clients. Un client ne peux avoir qu’un seul numéro de CNI et un numéro de CNI correspond à un unique client. Ce type de relation est toutefois extrêmement rare.
Tables et objets
Chaque famille d’objet est stocké dans une table. On a ainsi une table client, une table commande…
Chaque objet client dispose d’un clé primaire. Cette clé est un identifiant unique d’un objet particulier stocké dans la table. Cette clé unique permet ensuite de lier l’objet en question à un autre objet cible (par exemple une commande). Dans la table des commandes on trouvera une clé primaire (qui permet d’identifier formellement la commande), mais aussi une clé étrangère client qui permet de lier cette commande à un client.
Limites du modèle relationnel
Le type de modélisation relationnel est particulièrement efficace pour traiter les données provenant d’applications transactionnelles. Par exemple pour un site e-commerce l’utilisation d’une modélisation relationnelle est bien adapté. On parle de systèmes de type OLTP (OnLine Transaction Processing). Un système de facturation client est ainsi assez aisé à créer dans le cadre du paradigme relationnel : on aura la table client, la table facture, la table des acomptes…etc chacune étant reliée grâce aux clés primaires (d’un côté) et étrangères (de l’autre).
Le modèle multidimensionnel : des requêtes analytiques performantes et plus facile à écrire
Mais pourquoi donc aurait-on besoin d’ajouter un autre schéma ? La réponse est simple lorsque les bases relationnelles commencent à accumuler un volume de données important le temps nécessaires aux requêtes analytiques augmente significativement. Précisons bien d’emblé que seules les requêtes analytiques sont concernées. Par exemple voiloir calculer un taux de rétention sur une table regroupant l’ensemble des activités des utilisateurs peut s’avérer très couteux en temps de calcul.
Le modèle multidimensionnel permet aussi de réduire la difficulté d’écriture des requêtes qui dans le cadre des bases classiques peuvent vite devenir illisible. Et qui dit illisible, dit temps perdu par le développeur ! Ainsi on peut interroger plus facilement ces modèles tout en ayant des temps de réponses bien meilleurs.
Comparaison des requêtes SQL & MDX
Par exemple dans le cas d’un modèle relationnel (en supposant un schéma permettant cette requête); pour avoir le nombre distinct de commandes d’un produit de la catégorie X par client on pourrait avoir une requête comme suis :
1 | SELECT c.first_name , c.last_name, COUNT(DISTINCT o.id) |
On est obligé de faire une jointure sur plusieurs tables et la requête devient assez longue et peu élégante, de suite elle est plus complexe à débugger. Tandis qu’on aura une version plus courte de la requête avec l’aide du MDX (un simili SQL qui permet d’interroger des bases multidimensionnelles de manière plus simple) :
1 | SELECT [Measures].[Orders Count] ON COLUMNS, |
Beaucoup plus simple et lisible !
Dimensions, faits et mesures : le modèle en étoile
Voici un modèle d’organisation multidimensionnel (aussi appelé OLAP) :
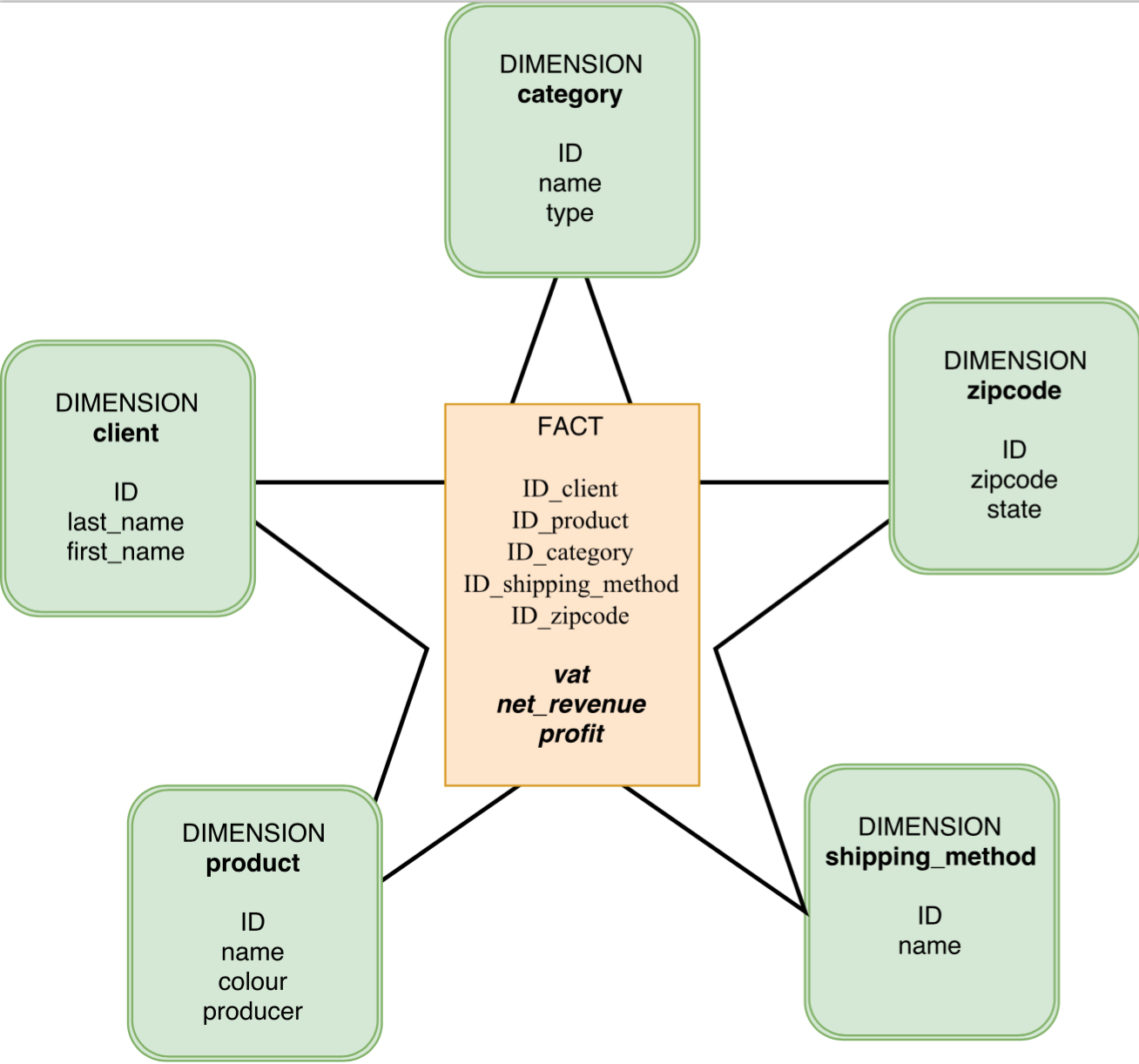
On voit donc qu’on organise la données en pensant d’abord aux analyses qui vont y être faite. Ici on veut pouvoir comprendre la répartition du profit et du revenu net en fonction du produit, du client, de la catégorie, du code postal de livraison, de la méthode de livraison ! On va donc créer nos dimensions d’analyse : on aura donc 5 dimensions. Ce qui se manifestera dans le schéma par 5 tables de dimensions.
A ces 5 tables de dimensions on ajoute une table centrale, qui est la table de fait (fact table). Cette table de fait va regrouper les clés étrangères des tables de dimensions (ID_client, ID_product, …) mais aussi nos mesures(ou metrics) : ici le profit, le revenu net et la TVA.
On voit donc bien maintenant pourquoi il s’agit d’un modèle en étoile. Les dimensions ne sont pas liées entre elles et c’est la table de fait qui fait le lien entre les mesures et l’ensemble des dimensions !
Les métiers peuvent interroger directement les bases !
Par la suite on peut donner la possibilité au métier d’interroger directement la base afin de faire des analyses à volonté à partir de ces dimensions. De nombreuses solutions d’interrogations existent. L’une de mes préférée est Saiku (http://www.meteorite.bi/) qui dispose d’une version open source ! Les métiers peuvent générer des tableaux à la volée en couplant les dimensions, sans avoir à maitriser le MDX !
Le modèle dispose encore de bien d’autres avantages et caractéristiques, j’essayerai ‘écrire à nouveau sur ce sujet passionnant.
Lectures :
- http://www.joyofdata.de/ : un blog passionnant sur la BI
- http://pentaho-bi-suite.blogspot.fr/ : un autre blog plus orienté Pentaho, mais tout aussi intéressant à suivre.