The term “Dependency Injection” has been created by Martin Fowler in 2004 [1]. The term has gained some hype with time and several colleagues presented me the concept.
I wanted to gain a better knowledge of it so I wrote this article that has 3 main objectives :
- Give a definition of the concept
- Illustrate it’s usage
- Make the reader understand why dependency injection may improve software
Vocabulary
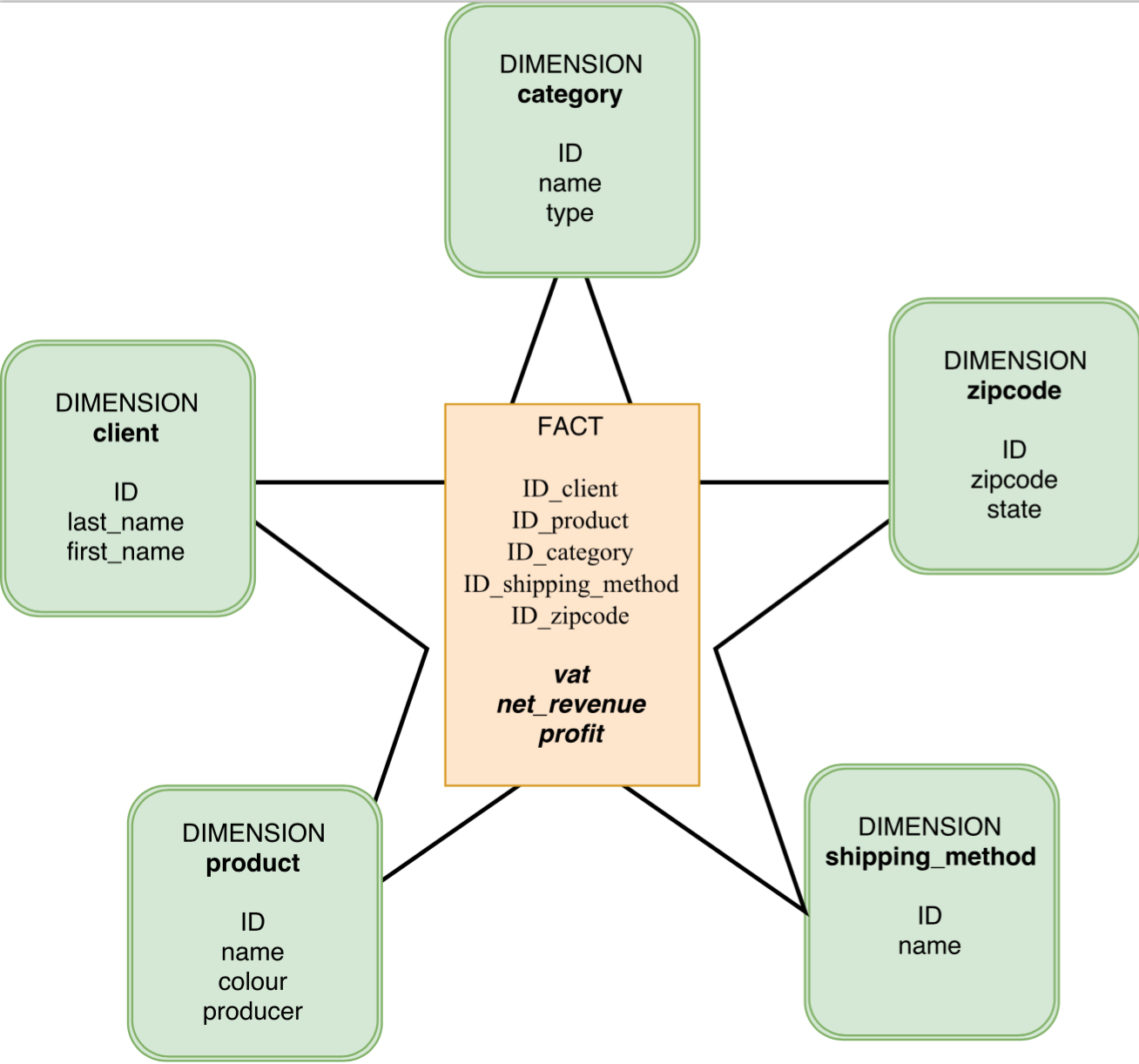
Dependency Injection is a technique related to inversion of control. The term “inversion of control” was born in 1988 in an article written by Johnson and Foote [5].
When we write an application that depends on a specific component we will need to call the component we want to use.
In this situation the developer is fully in control of what is happening in the program.
Now, if we use a framework, we can delegate to the framework numerous tasks like instantiating components (but not only). In this configuration control is inverted.
Many frameworks provide inversion of control. In this article we will focus on the Spring Framework (Java) that is built around this concept.
Dependency injection invert a very specific “aspect of control” [1].
To understand the concept, we need first to define precisely the terms involved here :
- Dependency : A piece of code that needs to be used in another piece of code. In object oriented programming world those pieces of codes are usually classes. We say that a class has a dependency when it needs to use another class. The first class is dependent from the second class. For instance the class responsible to render a web page has a dependency to the class responsible to query the database.
- Injection : in the medical world, an injection refers to the introduction of a liquid into the body of a patient. An injection is usually done by a doctor (or a nurse). We need three actors for performing injection : (1) the injector (the doctor), (2) the liquid, and the receiver (3).
The idea of “dependency injection” is to let the framework we are using inject our dependencies automatically when we need to use them. Frameworks usually provide in their core code and “injector” to perform this task.
To understand it better we will go through an example :
The example project
Our project is pretty simple. It’s a REST API server with a single endpoint :
1 | GET https://maximilien-andile.com/velo |
The server (maximilien-andile.com) exposes a GET endpoint (/velo).
The idea of this endpoint is to get the number of available bikes (from a self-service bike rental provider) at a particular station.
In order to send the response to the user our server will need to call the API of the self-service bike rental provider.
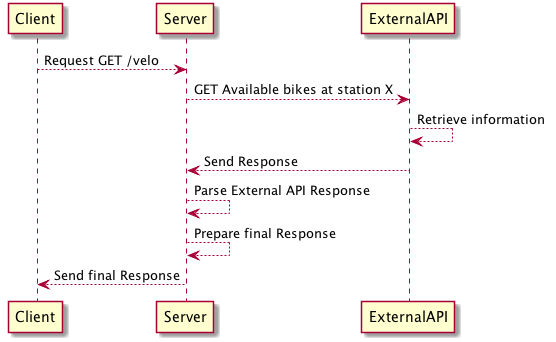
Two components, one dependency
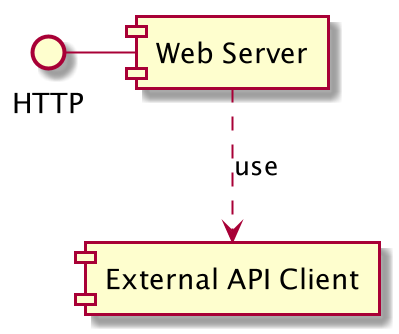
In our project we have two components :
- The web server : it will handle all incoming requests from the web. It has an HTTP interface
- The external API client : client that will call the self-service bike API.
Here the web server will use the external API client.
We have a dependency. The web server needs to use the external API client to handle incoming HTTP requests.
The web server is dependant of the external API client.
A first version of the project
We will draft a first version of the project to better understand the concrete manifestation of a dependency into the code.
The source code will be written in Java with Spring Boot.
The entry point
1 | package com.example.demovelo; |
Here we have the entry point of our program. It consists of a class named DemoveloApplication which contains a single
static function called main.
The REST Controller :
1 | package com.example.demovelo.controller; |
You see here that we have a class (with the annotation @RestController needed by Spring) and then a public method getBikesAtStationX.
This method has also an annotation @RequestMapping(path = "/velo",method = RequestMethod.GET). It allows the Spring framework
to map the request GET /velo received by our server to be mapped to this particular method.
In this method we are instantiating the second component BikeService which is responsible to call the JCDecaux API.
We then call the method bikesAvailableAtStation on the instance created bikeService.
The External API Client : BikeService
And here is the code of BikeService :
1 | package com.example.demovelo.service; |
Note here that we have not implemented the actual call to the JCDecaux API. (We juste return 42…)
What is wrong with this code ?
Memory usage will increase with server load
Each request to the REST Server will create an instance of BikeService. The memory consumption will increase with the server load.
It is not testable
What if we want to unit test the getBikesAtStationX method ? Here is an unit test example :
1 | package com.example.demovelo.controller; |
We have a BikeControllerTest class with a single method getBikesAtStationX, which is the method resposible to test getBikesAtStationX.
In this method we create an instance of the BikeController named bikeController and then we call assertEquals (from the junit Assertion Library).
This method takes two parameters : the expected result and the actual result. Here we check that 42 is equal to bikeController.getBikesAtStationX().
If we launch the unit tests it will pass (because bikeController.getBikesAtStationX() always return `42, hence the assertion is valid).
When we will develop getBikesAtStationX and call the external API the result will vary. Our test will fail.
We do not control the external API therefore we cannot base an unit test on it. Unit tests have to be isolated from external services.
We need to find a way to control the output of the method bikesAvailableAtStation.
Dependent components should only use a small interface
In our example the REST server is responsible to create a new instance of BikeService :1
2
3
4public int getBikesAtStationX(){
BikeService bikeService = new BikeService();
return bikeService.bikesAvailableAtStation("X");
}
It means that the dependent component is responsible to construct an instance of it’s dependency.
The BikeController should not be responsible of this task.
A modification to the BikeService constructor will break the BikeController.
In other words when we modify the implementation details of our components, every other components that depends on it need to be modified.
Implementation details should be hidden to the clients. Clients should only use on a small interface.
Note here that I have used the term client. When a component A uses a component B we say that the component A is a client of the component B.
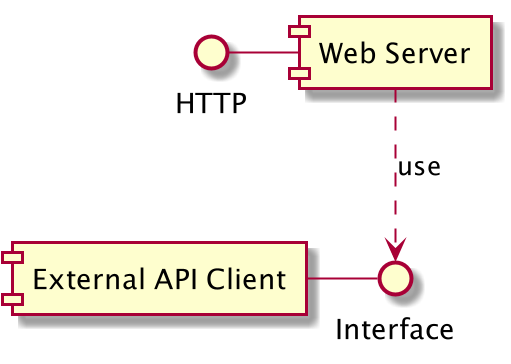
A new version of the project with dependency injection
The application entry point do not change. Only the BikeService and BikeController will change.
The new BikeService
The first step is to create an interface. This interface define a contract for any implementation of a BikeService :
1 | package com.example.demovelodi.service; |
Then we create a concrete implementation of that contract :
1 | package com.example.demovelodi.service; |
Here our class BikeServiceImpl implements the BikeService interface. To fulfill this contract we define the method bikesAvailableAtStation.
Note that we added 1 Spring Annotation and 1 java annotation :
@Service: allow the Spring framework to register the class as a bean (a component).@Override: Here we have an implementation of an interface, so at first sight this annotation seems useless, this class do not extend any class. The annotation was automatically provided by my IDE. After a quick look it seems that adding the annotation will force the compiler to check if we implemented correctly the interface…
The new BikeController
1 | package com.example.demovelodi.controller; |
We added the private property bikeService in our class (of type BikeService).
The we added a constructor to our class that takes as parameter a BikeService.
The method getBikesAtStationX did not change a lot, except that we do not construct an instance of BikeService in it.
Instead we are using the class property.
We never instantiate the BikeService in our controller, it will get instantiated by the Framework.
An injector, that is hidden by the framework will instantiate it.
Here is an UML Class diagram that show the relation between classes :
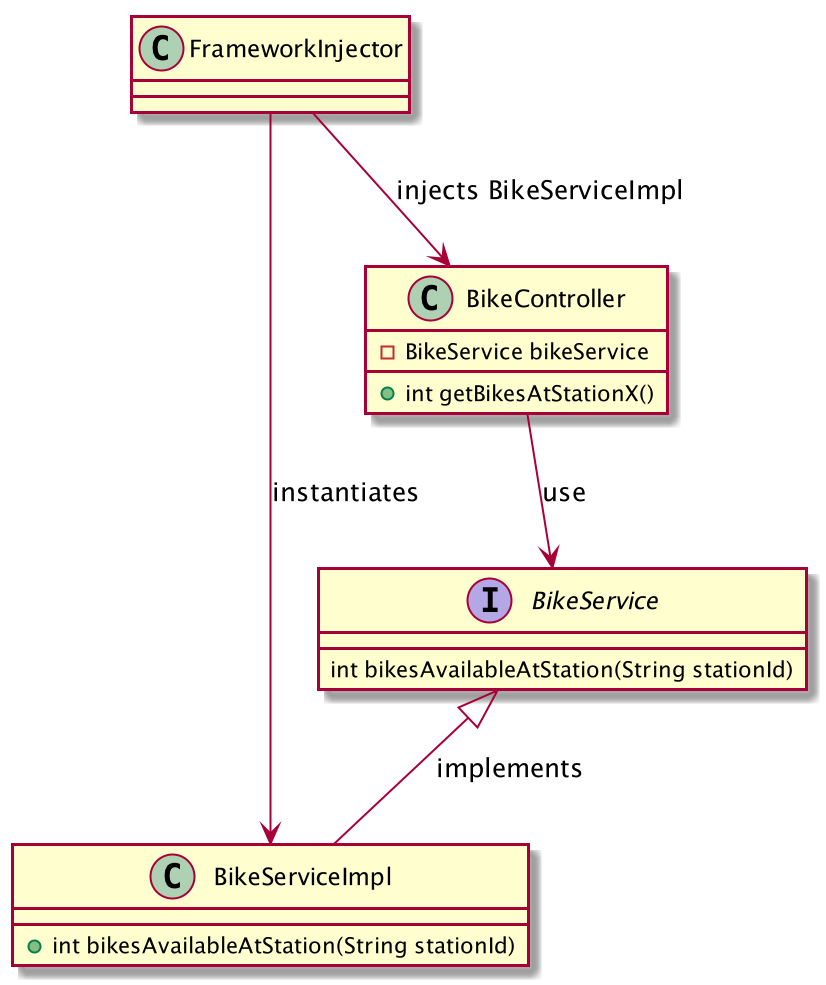
- The
BikeServiceImplclass implements theBikeServiceinterface - The
BikeControlleruses theBikeServiceinterface - The
FrameworkInjectorwill instantiate theBikeServiceImplclass and inject it into theBikeController.
Unit test
The first version of the BikeController was impossible to test.
The second version of the controller requires an interface in it’s constructor. As a consequence we can use a mocked BikeService instead of the actual implementation of the BikeService.
Here is the mocked implementation :
1 | package com.example.demovelodi.controller; |
Here instead of calling the real API we are directly returning a fixed integer, allowing us to assert that the controller returns what is expected :
1 | package com.example.demovelodi.controller; |
In the setUp function (that will be run before each tests) we create an instance of our mocked implementation. Then we set the property bikeController with a new instance of the BikeController constructed with the instance of the mocked Service.
The test (in the method getBikesAtStationX) will assert (verify) that 65 is actually returned by this.bikeController.getBikesAtStationX().
Comparison of the two controllers
To better see the differences between the two version here are the two controllers
- Without Dependency Injection :
1 | package com.example.demovelo.controller; |
- With DI :
1 | package com.example.demovelodi.controller; |
Dependency injection and maintainability
In this section I will focus on the effects of dependency injection on software maintainability.
What is software maintainability ?
There are two definitions of “software maintainability” :
The ISO/IEC defines it as :
the capability of the software to be modified
For Matinlassi Mari and Niemelä Eila [2], the maintainability is :
The ease with which a software system or component can be modified or adapt to a changed environment.”
The definition emphasis that a maintainable software can be changed without pain for the future developers that will work on the project.
Why do we care about maintainability ?
When you care about maintainability you care about your peers but also about the company that employs you.
A component that is hard to make evolve will increase the budget of a project.
Coupling can be used to measure maintainability
The previous definition is clear. A software is maintainable if we can change it easily.
The characteristic of “changing easily” is very subjective and therefore hard to measure.
We can use a proxy to detect a maintainable software : coupling.
A system is said to be highly coupled if it’s different parts are highly interdependent. In opposite a system is loosely coupled if it’s parts it are less interdependent.
Coupling can be measured by code parsers. In 1999 a pretty famous paper written by Briand, Daly, & Wust defined different metrics around the concept of coupling [4].
Two measures of coupling
From the Briand, Daly, & Wust [4] we can remember two metrics :
CBO (Coupling Between Objects) can be calculated for any class. It counts the number of couples there is between the given class and other classes.
A couple is created when a class use methods or attributes of the other class. If the class is used by two other class the CBO is 2.RFC (Response For A Class) is the number of methods that can be called when a message is received on an object of a class [4].
This metric gives an idea of the level of testability of the software created.
If only one method can be called for each message received on the object, building an unit test is easy. When for a single message 10 methods can be called and those method can also call 10 more methods, writing unit tests is not an easy task.
Those two metrics allow us to give a precise definition of coupling.
The more dependency injection the less coupling
Razina & Janzen in a paper from 2007 wanted to demonstrate that “significantly reduces dependencies of modules in a piece of software, therefore making the software more maintainable.”.
They calculated “cohesion and coupling metrics” on 40 projects (20 projects that were using Dependency Injection, 20 without dependency injection).
The study did not succeed into proving the hypothesis. But they demonstrate that :
a trend of lower coupling in projects with higher dependency injection percentage (more than 10 %) was evident
Using dependency injection does not automatically reduce coupling. But when it is used software coupling metrics seems to be lower.
Further reading
- [1]Inversion of Control Containers and the Dependency Injection pattern, Martin Fowler
- [2] Mari, M. (2003, September). The impact of maintainability on component-based software systems. In null (p. 25). IEEE.
- [3] Razina, E., & Janzen, D. S. (2007). Effects of dependency injection on maintainability. In Proceedings of the 11th IASTED International Conference on Software Engineering and Applications: Cambridge, MA (p. 7).
- [4] Briand, L. C., Daly, J. W., & Wust, J. K. (1999). A unified framework for coupling measurement in object-oriented systems. IEEE Transactions on software Engineering, 25(1), 91-121.
- [5] Johnson, R. E., & Foote, B. (1988). Designing reusable classes. Journal of object-oriented programming, 1(2), 22-35. (article is here)