Qu’est ce qu’un script shell
Un script “shell” est un programme écrit pour être exécuté via l’interpréteur de commande UNIX. Ces scripts sont facile à générer et suivent les patterns des langages de programmation communs. Ainsi on a la possibilité de créer des boucles et des structures conditionnelles par exemple.
Un script shell est dans les fait un fichier avec l’extension sh. On l’exécute en ouvrant cmd sous windows, ou le terminal sur macOS. La commande permettant d’executer un script shell est la suivante:1
sh name_of_the_script.sh
NB : Par habitude on rajoute un sigle dollar devant la commande. Il s’agit juste d’une convention permettant d’indiquer au lecteur que cette commande doit être exécutée dans le terminal.
Itérer sur les lignes d’un fichier via shell
Afin de lire les lignes d’un fichier les unes des autres on peut utiliser la structure for. For indique à l’algorithme qu’il faut itérer pour chaque élément d’un input (ici l’ensemble des lignes de notre fichier) :
1 | location_of_the_url_file = "./urls.txt" |
Dans un premier lieu on déclare la variable location_of_the_url_file qui stocke l’emplacement de notre fichier relativement à notre dossier de travail.
Dans un second temps on va récupérer l’ensemble des lignes de notre fichier via la commande :1
`cat $location_of_the_url_file`
Récupérer le contenu d’une page web via wget
wget est un outil de téléchargement très puissant. On peut donc l’utiliser pour télécharger le contenu d’une page web directement depuis le terminal. Il faut d’abord bien s’assurer de l’avoir installer sur sa machine.
Si ce n’est pas le cas on peut utiliser la commande brew install wget. Homebrew est un gestionnaire de dépendance très pratique qui permet des installations rapides. Pour plus d’information voici la page : http://brew.sh/index_fr.html
1 | wget -O ./pages/wiki.html $url |
La commande suivante permet de télécharger la page dont l’url est $url et de stocker cette dernière dans le dossier pages sous le nom wiki.html. Le téléchargement dans un répertoire cible est géré par la commande -O.
Créer un dump en format plain text de notre page html grâce à lynx
Lynx est un outil permettant la manipulation de pages HTML. Il s’agit en fait d’un navigateur en mode ligne de commande. Une sorte de chrome version simplifiée.
Pour accéder à google depuis votre terminal :
1 | lynx http://www.google.fr |
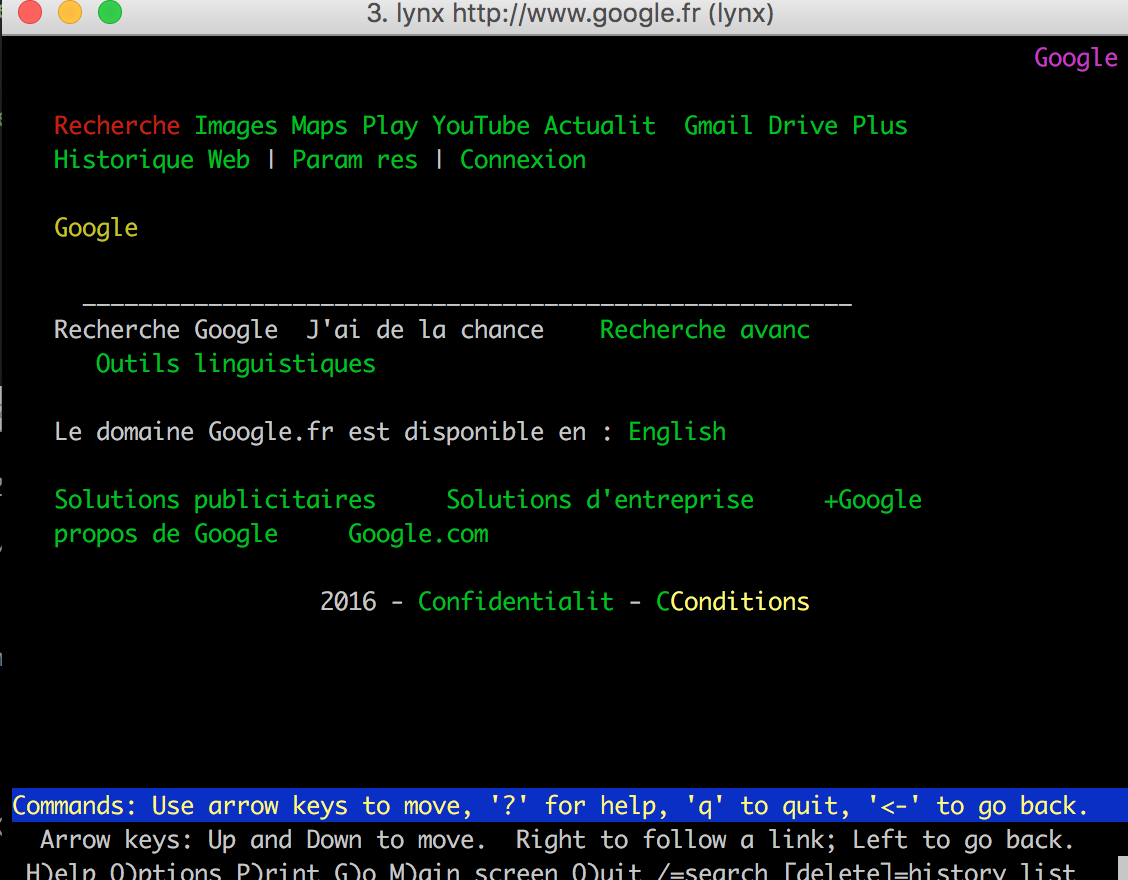
On peut donc produire une version .txt de notre page
1 | lynx -dump $url >./plain_text/page_version_txt.txt |
Cette version txt de nos pages web nous permettra de nous livrer à des analyses de type “NLP” (Natural Language Processing). Nous traiterons plus en détail cet aspect dans un prochain billet.
Voici le code complet du programme : https://github.com/maximilienandile/shell_web_page_to_plain_text